Enenlhet vowel research
This project includes three phonetic studies of Enenlhet vowels, focusing on a robust quantitative acoustic description of the inventory.
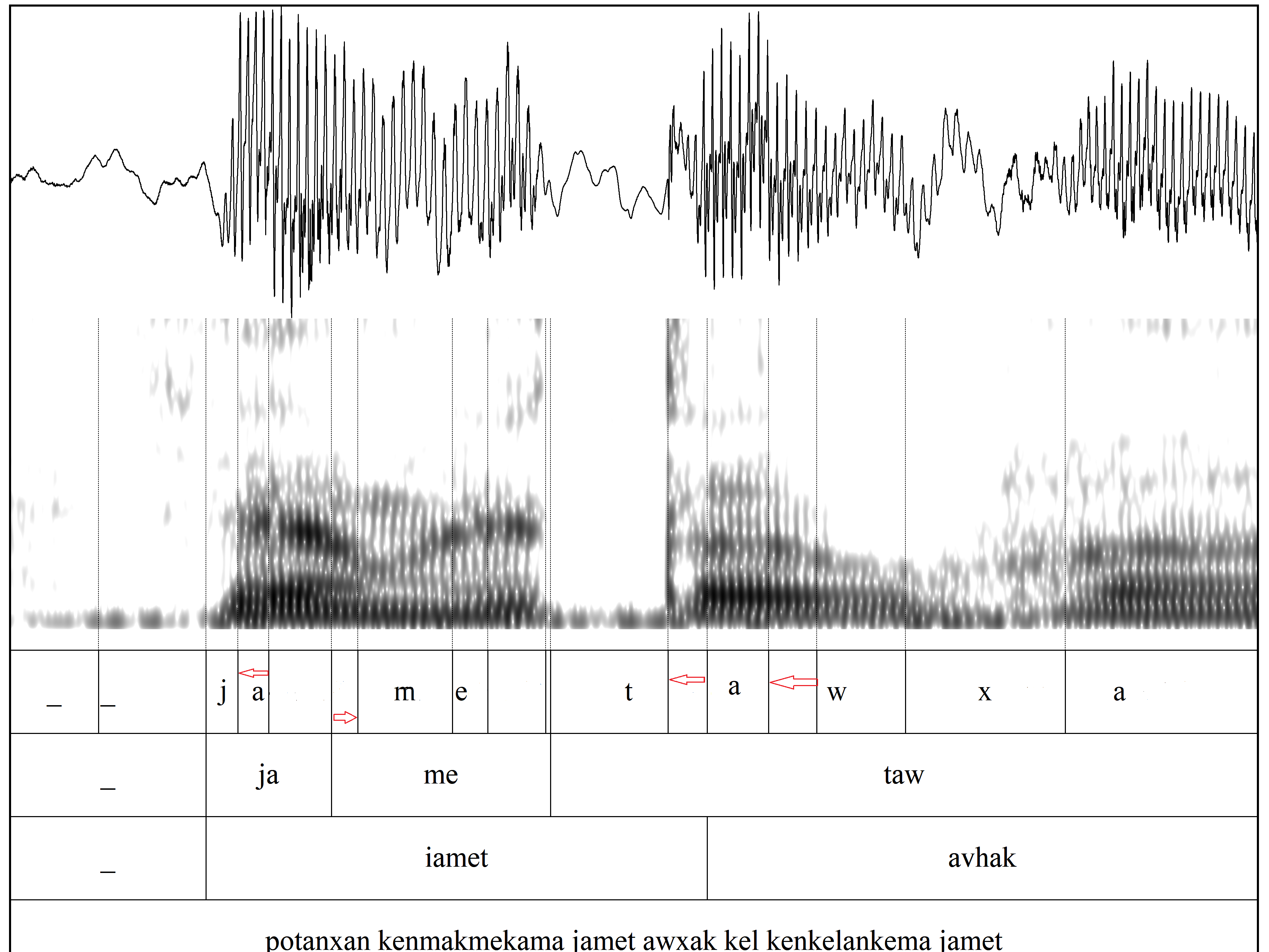
This project uses the Enenlhet language documentation corpus to perform a series of corpus studies investigating the acoustics of Enenlhet [tmf] vowels. The corpus includes about 3.5 hours of naturalistic speech (narratives and interviews), recorded, transcribed in Enenlhet and translated to Spanish by Raina Heaton and Manolo Romero. These data were force-aligned using EasyAlign, a Praat plugin. The alignment was untrained, as there is no trained acoustic model of Enenlhet; the alignment used the Spanish with seseo model. Alignment was hand corrected to accurately represent segment boundaries. A discussion of the accuracy and utility of this untrained forced alignment methodology was presented at CILLA X.
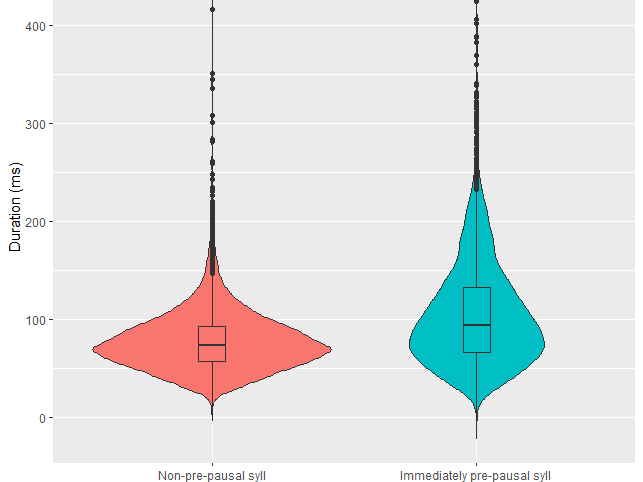
The first of the three studies examines vowel duration using a Linear Mixed Effects model run in R. The model examines the effect of a vowel's position within a word, the word's position with respect to a pause, the voicing of the following consonant, and syllable structure. It also accounts for random variation due to speaker and lexical item. The results of this analysis show that vowels are longer immediately before a pause, in open syllables, and before voiced consonants, with some interactions between these variables. The analysis does not find evidence of a fixed stress position or of phonemic vowel length, although sister languages (e.g., Enxet) have been described to contrast long and short vowels. This research was presented as a poster at ICPhS in 2023.
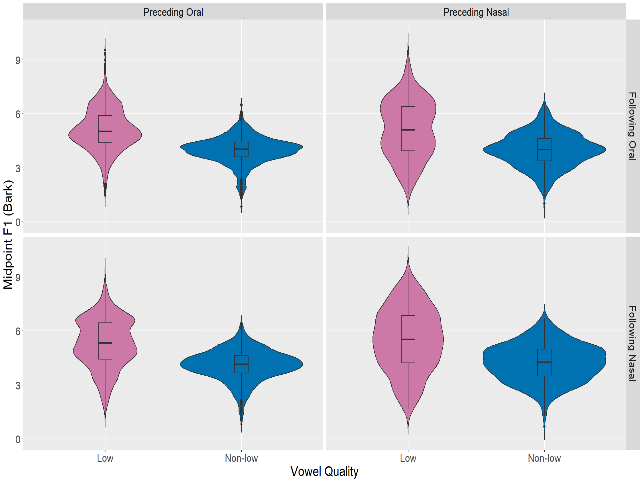
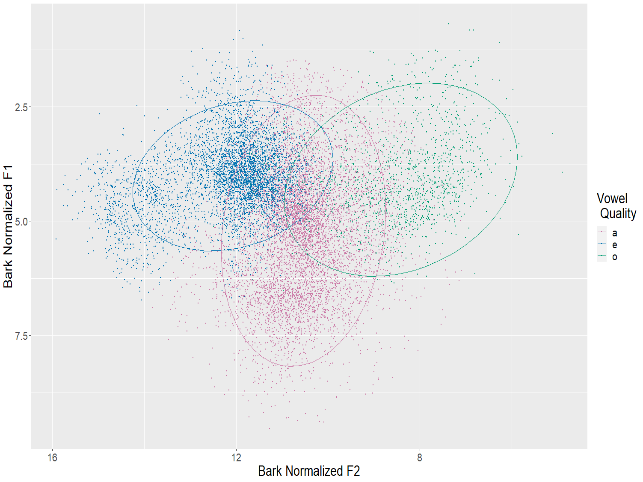
The second study examines vowel quality, as Enenlhet has a cross-linguistically unusual vowel inventory of just three vowels: /a, e, o/. A Linear Mixed Effects analysis examined the effect of preceding and following consonant place of articulation, as well as syllable structure and vowel duration. Results suggest three vowel categories, with more variation in the F2 dimension than the F1 dimension; these results are congruent to previous qualitative descriptions of Enenlhet and its sister languages. The F1 values for non-low vowels (/e, o/) are roughly similar to the F1 values reported for mid vowels in languages with five-vowel (/a, e, i, o, u/) inventories, suggesting that the IPA labels /e, o/ are appropriate. Vowels are raised adjacent to /j/ and lowered before nasals and uvular /q/. F2 is lowered adjacent to labial sounds and raised adjacent to palatals. There is a high degree of variability overall, both between speakers and in how each vowel quality interacts with the adajcent consonants.
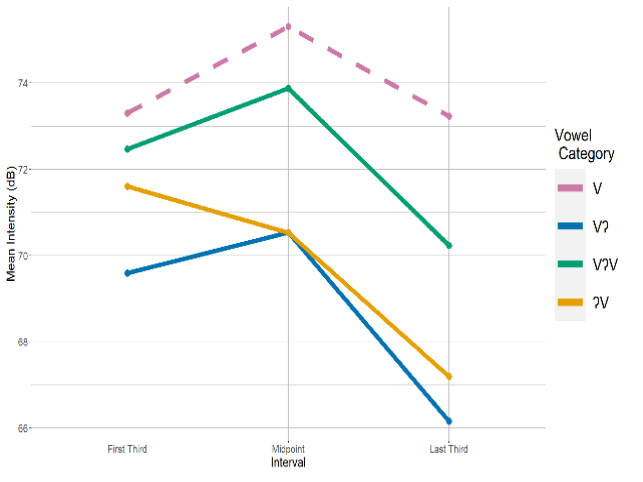
The third study investigates voice quality, specifically the effect of an adjacent glottal stop consonant. Qualitatively, I have observed substantial variation in voice quality in the corpus, including for Vʔ, ʔV, and VʔV (e.g., /aʔa, eʔe, oʔo/) sequences, but no acoustic analysis of voice quality exists in Enenlhet. The analysis shows that adjacent glottal stops trigger the expected changes in H1-H2, overall intensity, and harmonics-to-noise ratio. However, no differences in the timing of these acoustic changes were found, contra to expectations based on the qualitative observation that these cues tend to be most extreme in the part of the vowel closest to the adjacent glottal stop. Future research using a more fine-grained time dimension and clearer recordings is necessary to investigate potential differences between these categories.
During the course of this research project, I have recruited and trained three undergraduate research assistants to assist with data processing and analysis. The insights, assistance, and knowledge they have afforded me in processing and making sense of these data are invaluable. This research was funded by NSF-DDRIG-DLI No. 2024000; any opinions, findings, conclusions, or errors in this project are my own and do not necessarily reflect views of the NSF.